
Turn your storage servers into highly available cluster appliances
Installed and ready for enterprise use within minutes
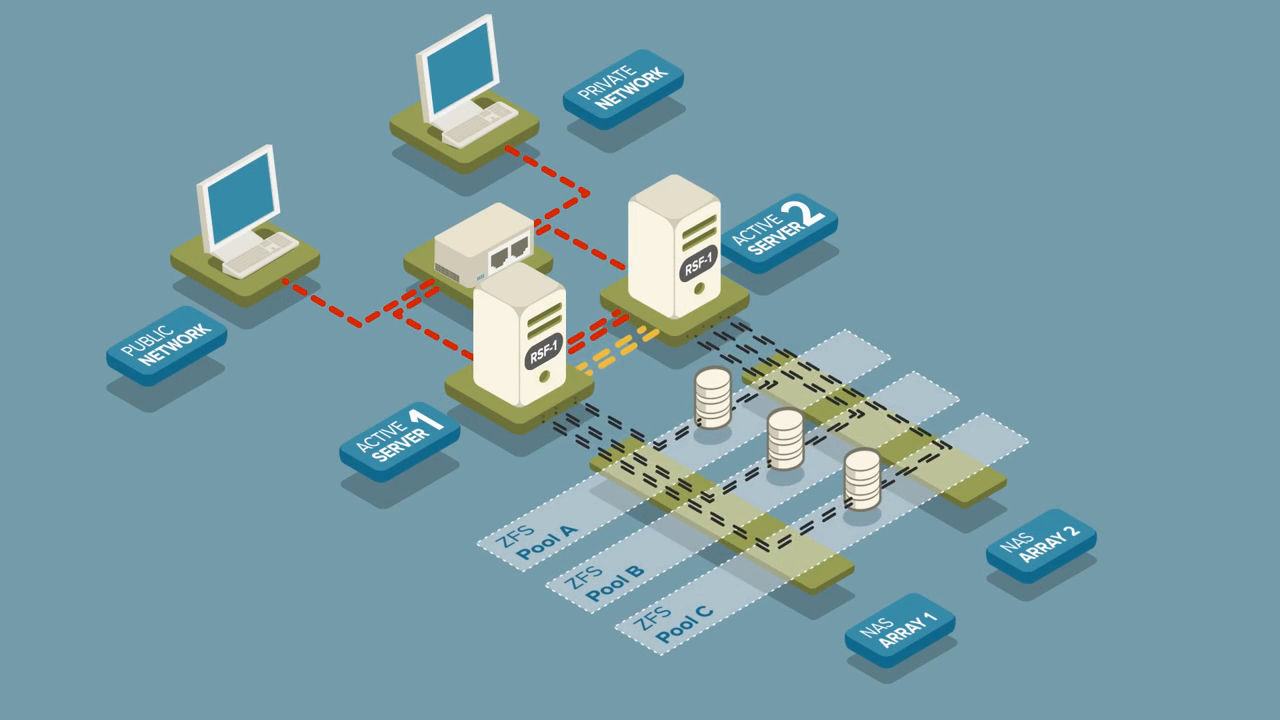
Built upon decades of real commercial experience, RSF-1 is the software-defined enterprise-class high-availability cluster product of choice for today's operations who are serious about maintaining access to their services and data

Shared nothing ZFS High Availability Clustering Available now with RSF-1 for ZFS
Deploy a ZFS Storage Cluster without shared storage in minutes
High-Availability.com recognise that for some use cases, a shared-storage Cluster topology is not always the best solution for High Availability requirements, whether due to cost or location limitations, and so we are delighted to now offer our Shared Nothing solution
Our Solutions
User Customisation
Protect your critical business application, database server, webserver, etc., using our enterprise grade cluster software by including your own startup and shutdown processes withing the RSF-1 framework.
Integration Support
Utilise the expertise of our HA Professional Services Team to help you get the best from your RSF-1 integration. Please ask us if you are at all unsure.
Multiple O/S Support
RSF-1 provides the same resilient functionality irrespective of your choice of operating system. So whether you prefer Solaris, Linux, BSD or one of their many variants there is a download for you. Don't see what you need? Then get in touch!
Watch RSF-1 in action
See how RSF-1 can be used to create a highly available ZFS appliance
Enterprise Solutions
User Customisation
Protect your critical business application, database server, webserver, etc., using our enterprise grade cluster software by including your own startup and shutdown processes withing the RSF-1 framework.
Integration Support
Utilise the expertise of our HA Professional Services Team to help you get the best from your RSF-1 integration. Please ask us if you are at all unsure.
Multiple O/S Support
RSF-1 provides the same resilient functionality irrespective of your choice of operating system. So whether you prefer Solaris, Linux, BSD or one of their many variants there is a download for you. Don't see what you need? Then get in touch!
User Customisation
Protect your critical business application, database server, webserver, etc., using our enterprise grade cluster software by including your own startup and shutdown processes withing the RSF-1 framework.


















