ZFS
Pools
The Pools page is used to both create zpools and to cluster them to create a service. The main page shows the pools discovered on a local node:
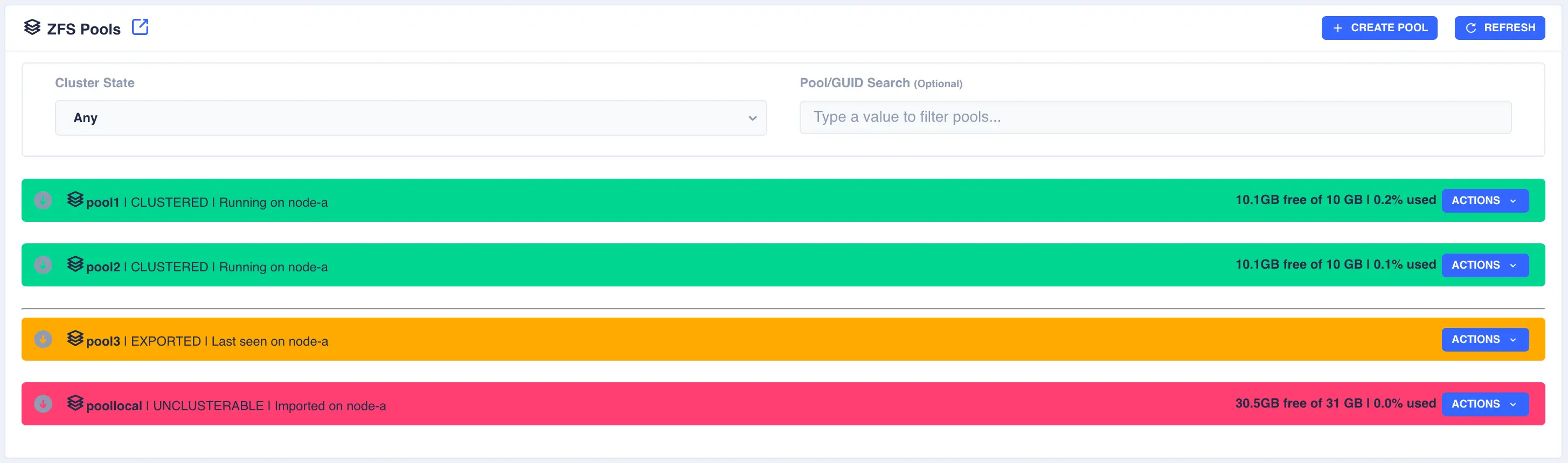
Clusterable pools
For shared storage all of a pools devices must be accessible by both nodes in the cluster; this is normally achieved using SAS drives in a JBOD connected to both nodes (commonly referred to as a Dual Ported JBOD).
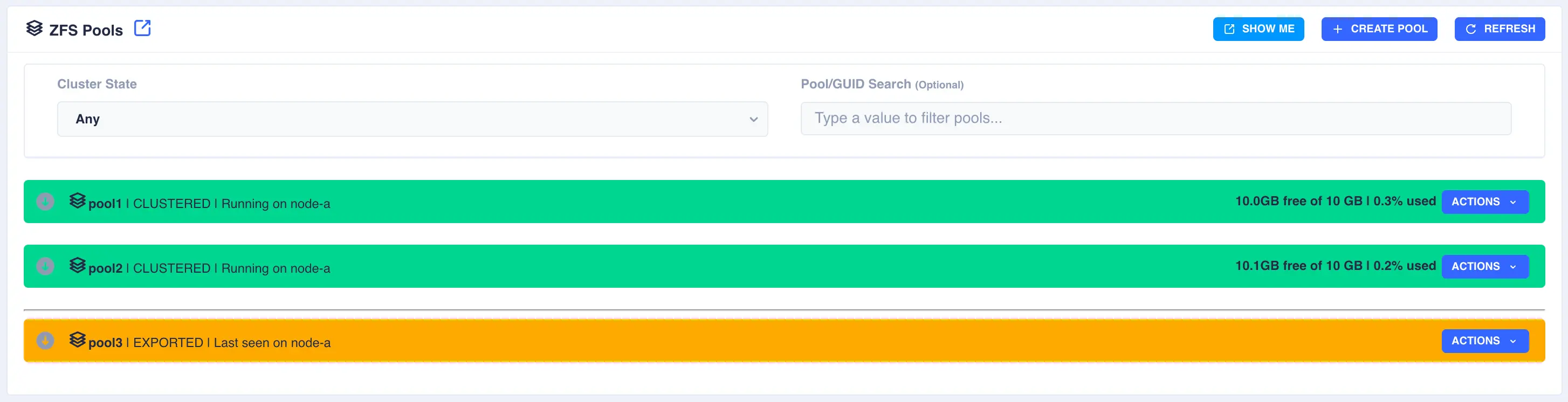
In the above example pools pool1 and pool2 are both clustered and running on node-a, pool3 is an exported, unclustered pool
and poollocal is only visible to node-a and therefore cannot be clustered.
Creating a Pool
To create a zpool click the + CREATE POOL button on the main pools page. You will then be presented with
the pool configuration page:
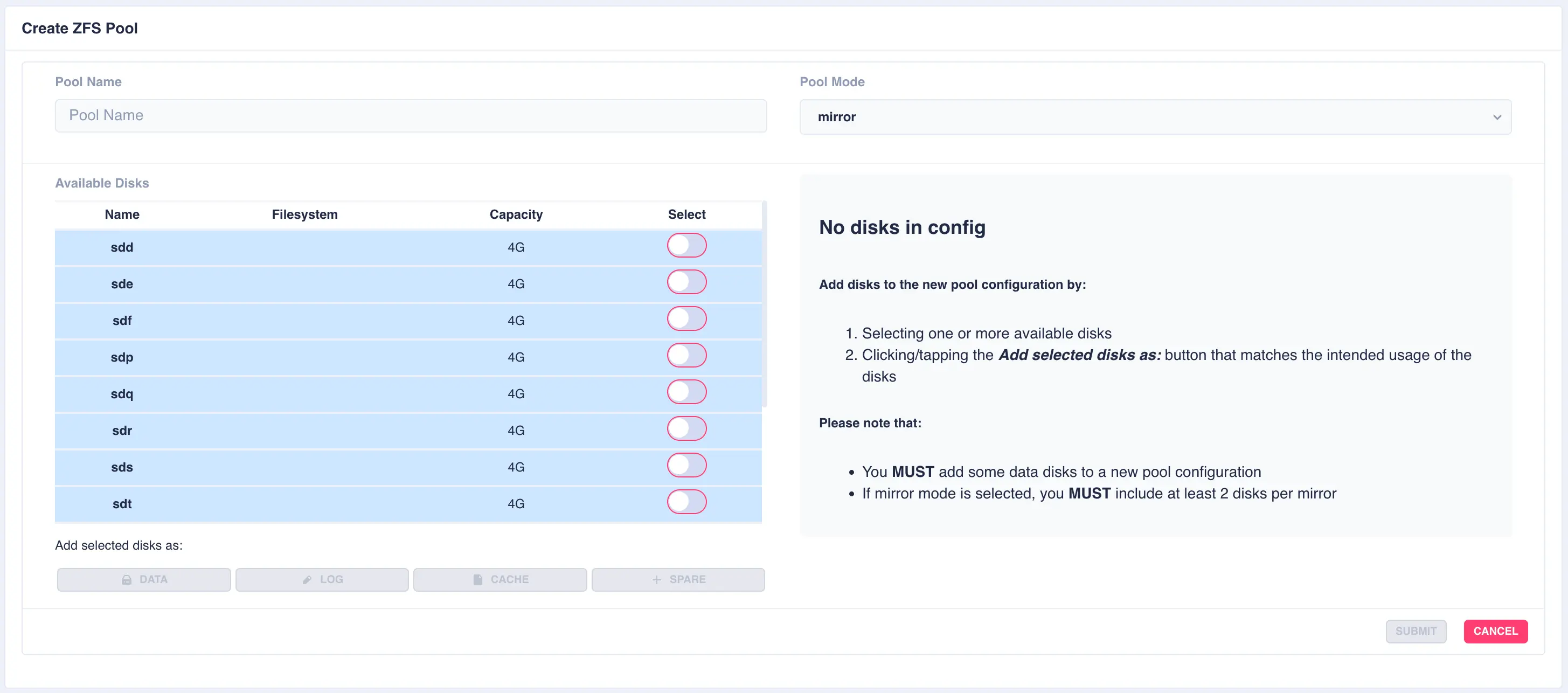
Fill out the Pool name field and select the desired structure of the pool from the Pool Mode list.
The cluster supports three types of layout when creating vdevs for a pool:
raidz2- Two of the drives are used as parity drives, meaning up to two drives can be lost in the vdev without impacting the pool. When striping raidz2 vdevs together each vdev can survive the loss of two of its members.mirror- Each drive in the vdev will be mirrored to another drive in the same vdev. Vdevs can then be striped together to build up a mirrored pool.jbod- Creates a simple pool of striped disks with no redundancy.
RAIDZ2 Pool
For this example a RAIDZ2 pool consisting of two five drive vdevs striped together, a log, a cache and a spare will be created. Five disks are selected for the first vdev, the desired Pool Name entered and raidz2 chosen from the Pool Mode list:
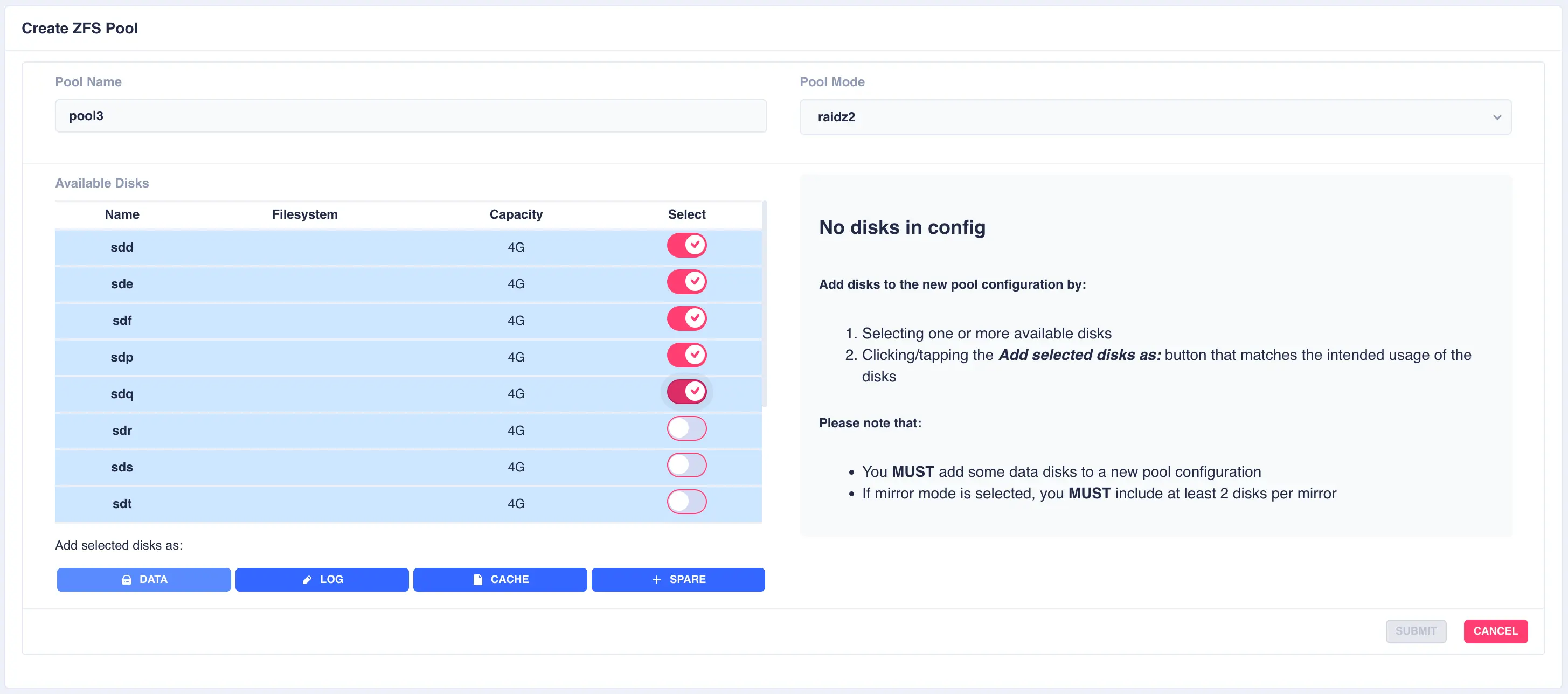
Click on DATA from the Add selected disks menu to configure the first vdev:
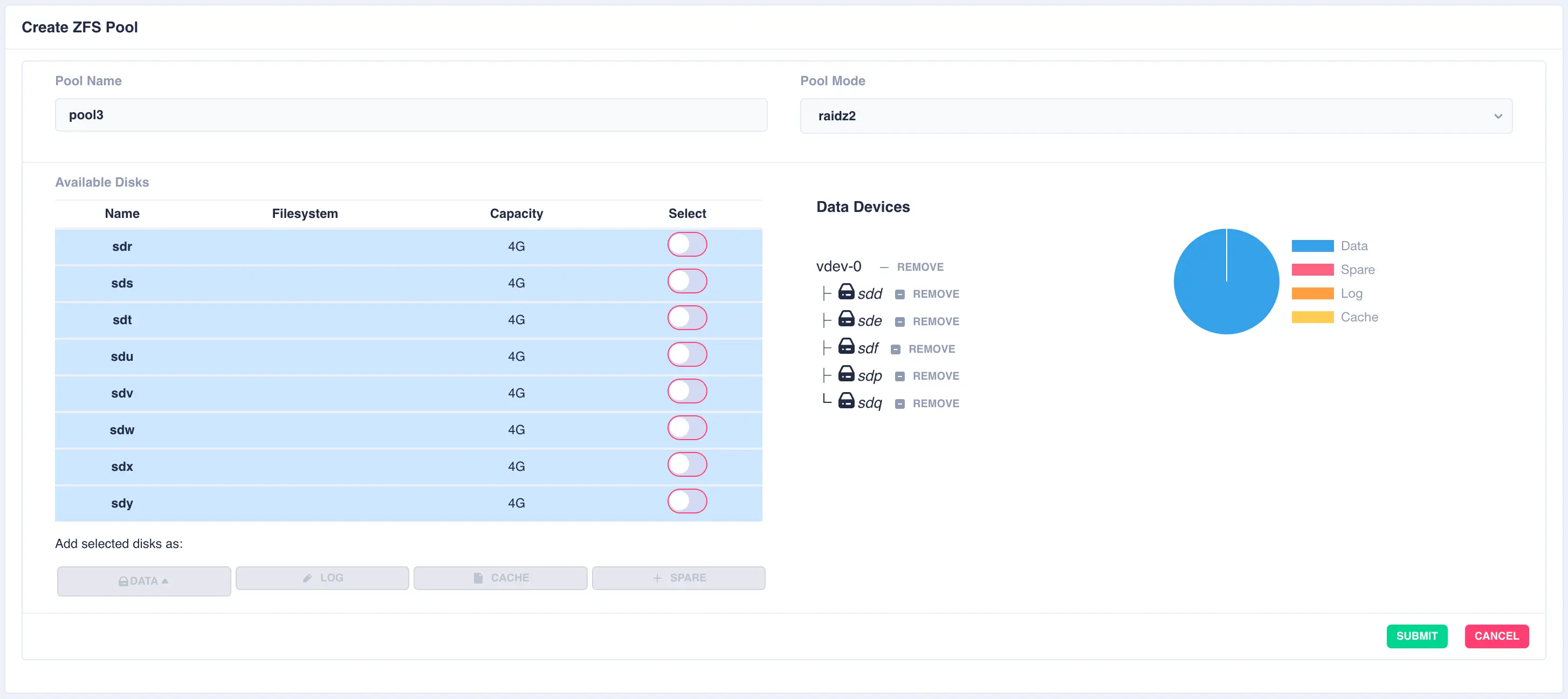
Next the second vdev is added, again using five drives, but this time selecting + New vdev from the DATA menu:
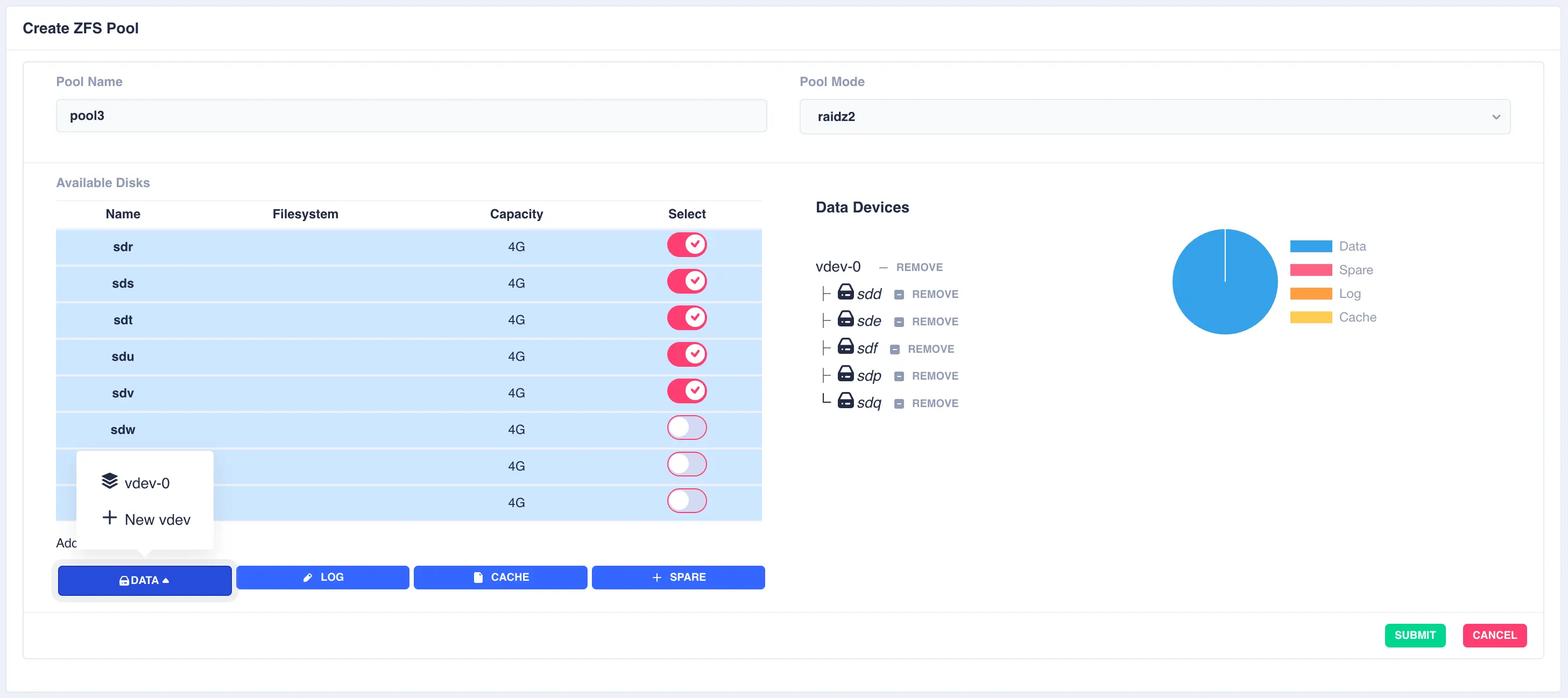
The resulting configuration depicts the two vdevs striped together:
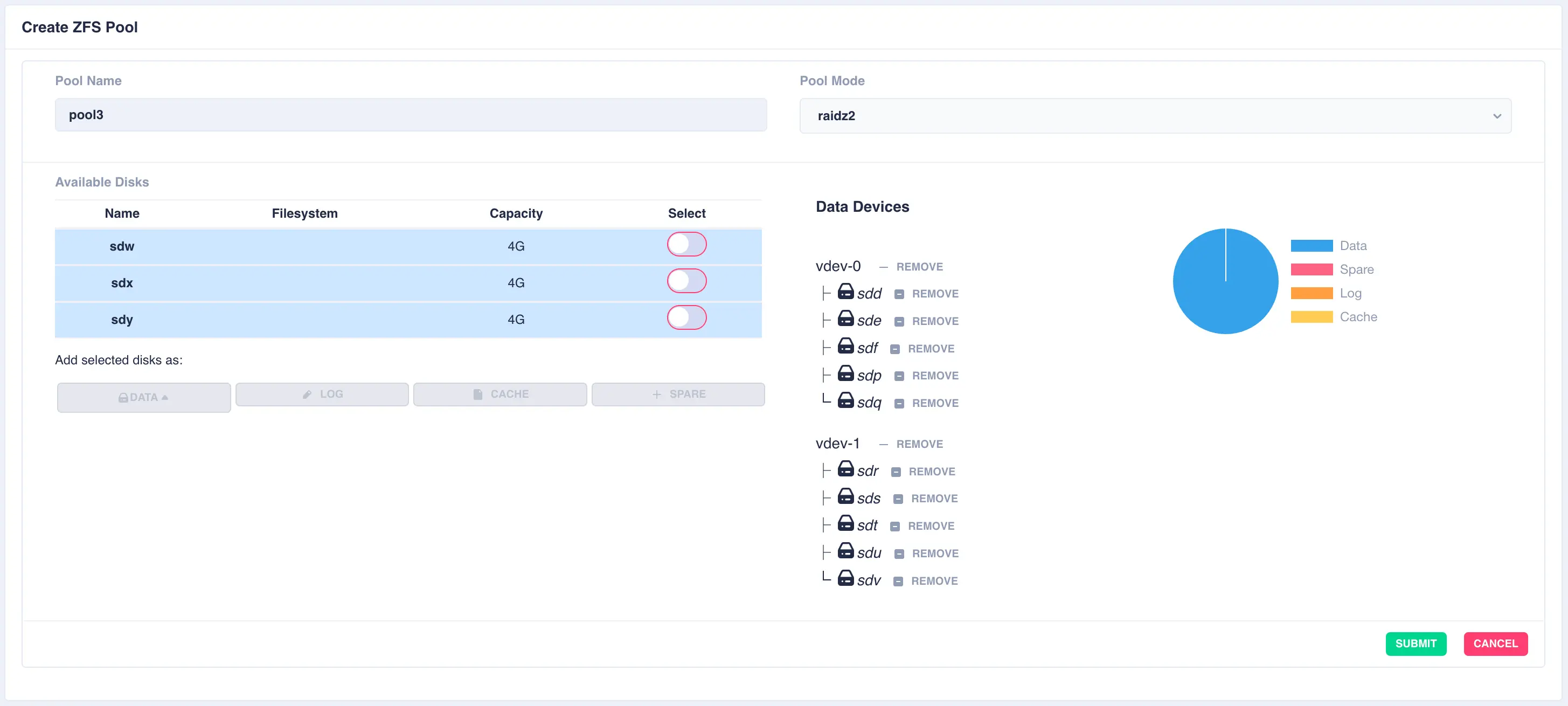
Next a log disk is added by selecting one of the remaining available drives and clicking the LOG button:
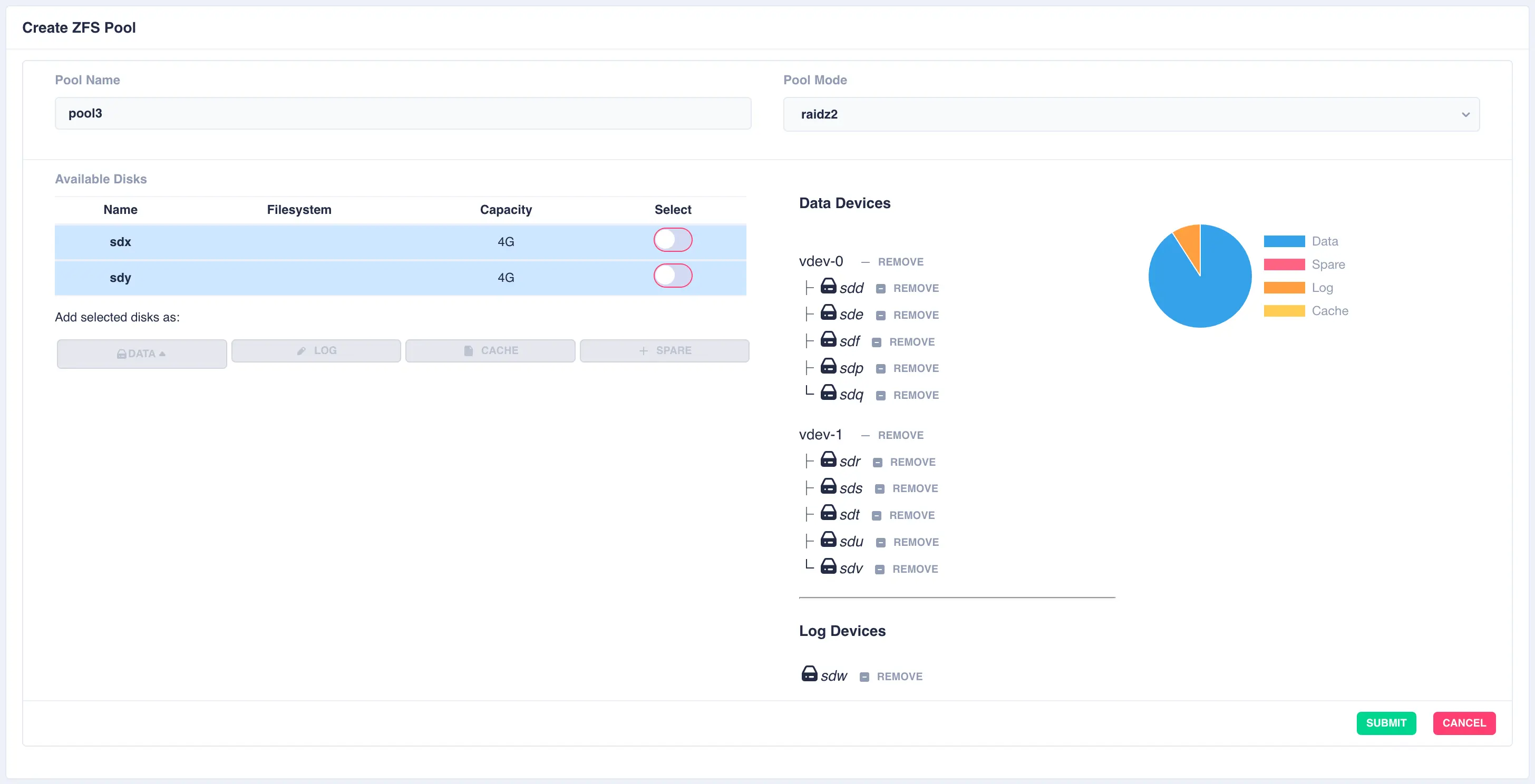
The same is done for a cache and spare device giving the final configuration:
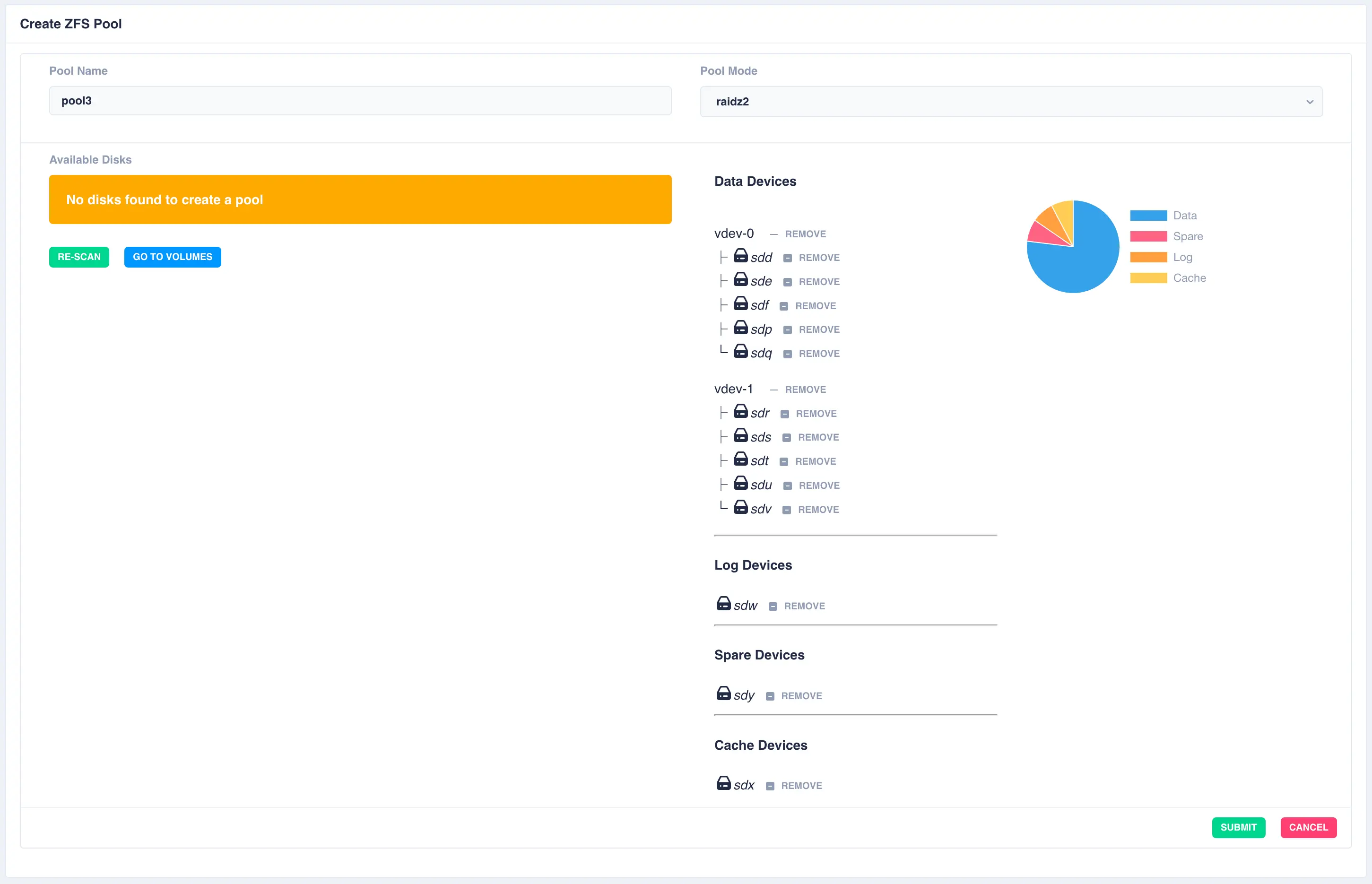
Finally click SUBMIT. The pool will now be created and will show up in the main pools page. Select
the pool to show the pool details - device information can also be shown by clicking Show on the devices
line:
Mirrored Pool
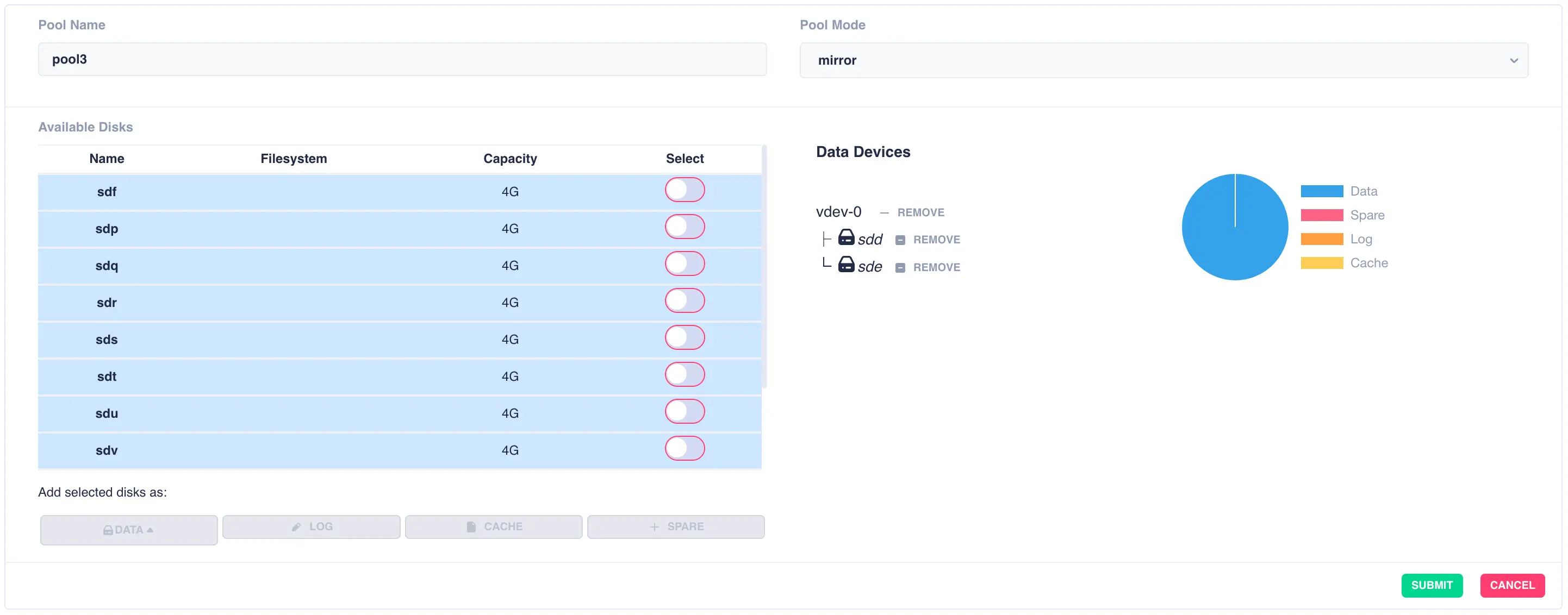
Mirrored pools are created by striping together individual mirrored vdevs.
Start by creating an individual mirrored vdev (in this example a two way mirror is created, but three, four way, etc. mirrors can be created if required):
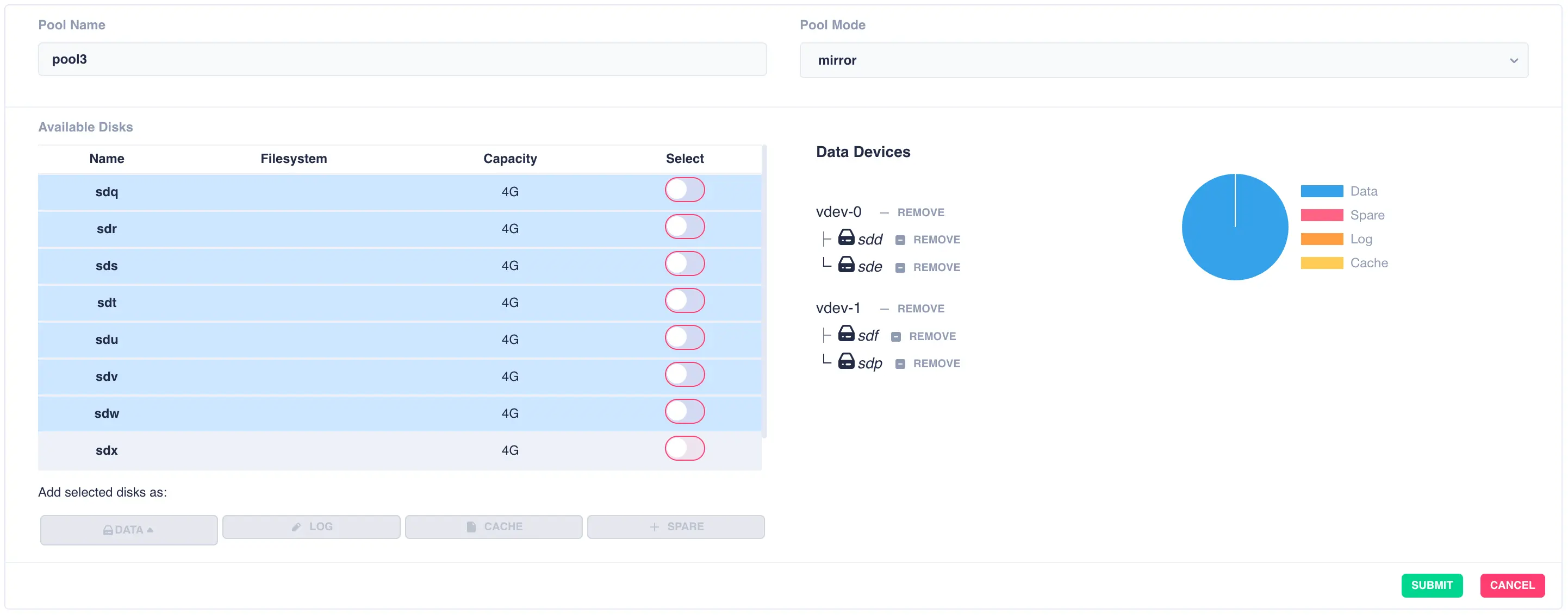
Continue adding mirrored vdevs as required:
Finally click SUBMIT. The pool will now be created and will show up in the main pools page.
JBOD Pool (single stripe)
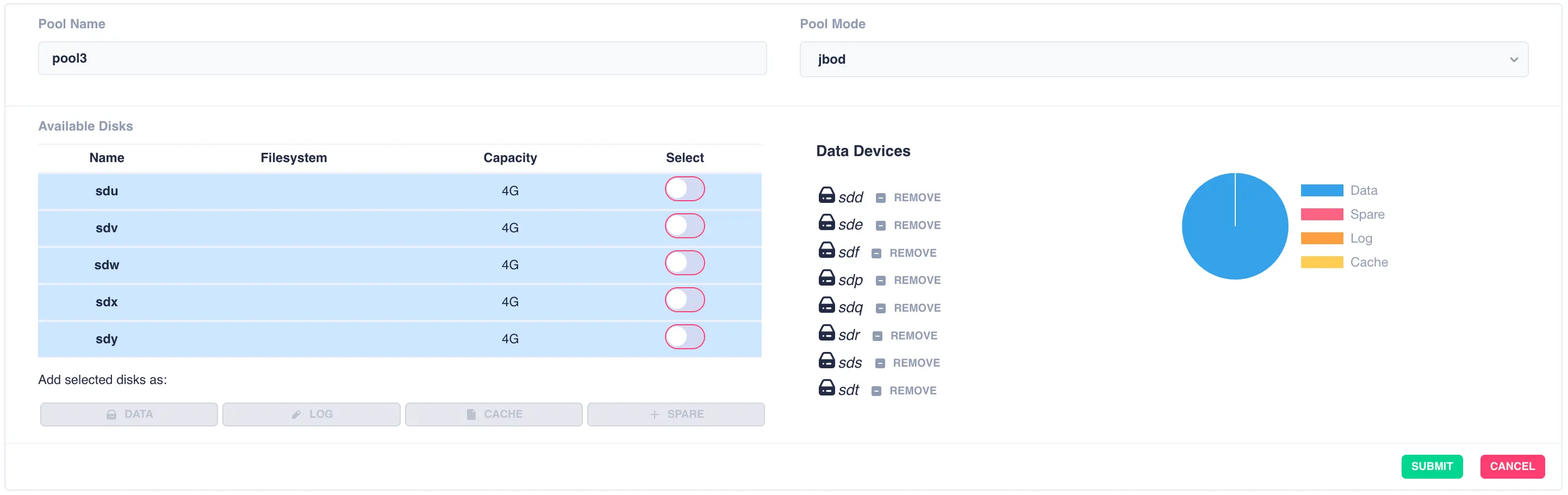
A jbod pool is a stripe of disks in a single vdev with no redundancy. Select individual disks and add them
to the vdev using the data button:
Finally click SUBMIT. The pool will now be created and will show up in the main pools page.
Preparing a Pool to Cluster
Pools must be imported on one of the nodes before they can be
clustered. Check their status by selecting the Pools option on the
side menu.
Shared-nothing clusters
For a shared-nothing cluster, the pools will need
to have the same name and be individually imported on each node
manually.
In the following example pool1 and pool2 are already clustered and pool3 is going to be added to the cluster:
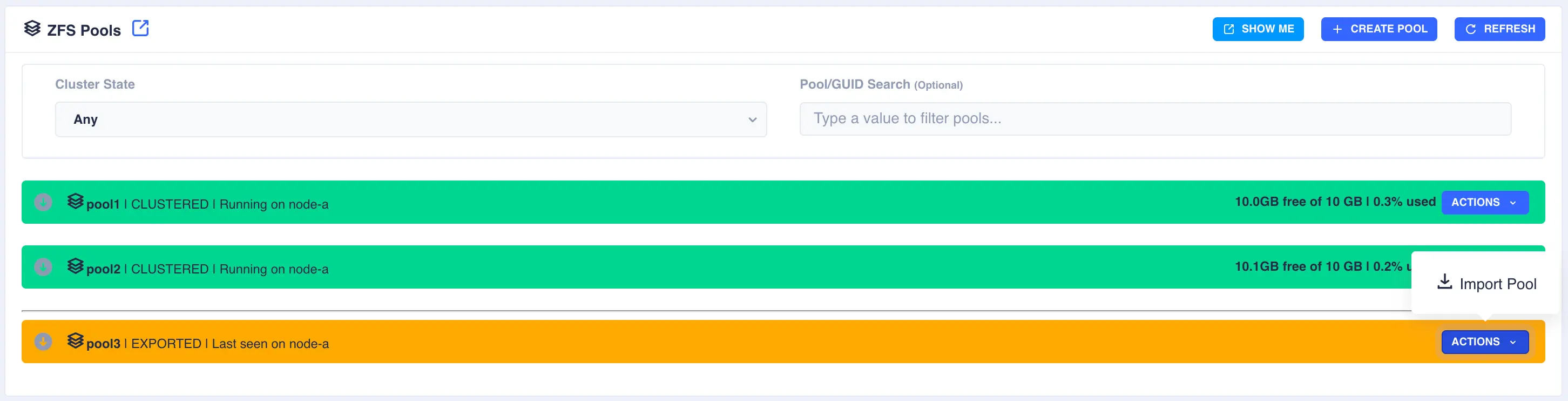
Firstly the pool need to be imported; select the Import Pool item from the Actions menu:
The status of the pool should now change to Imported and CLUSTERABLE:
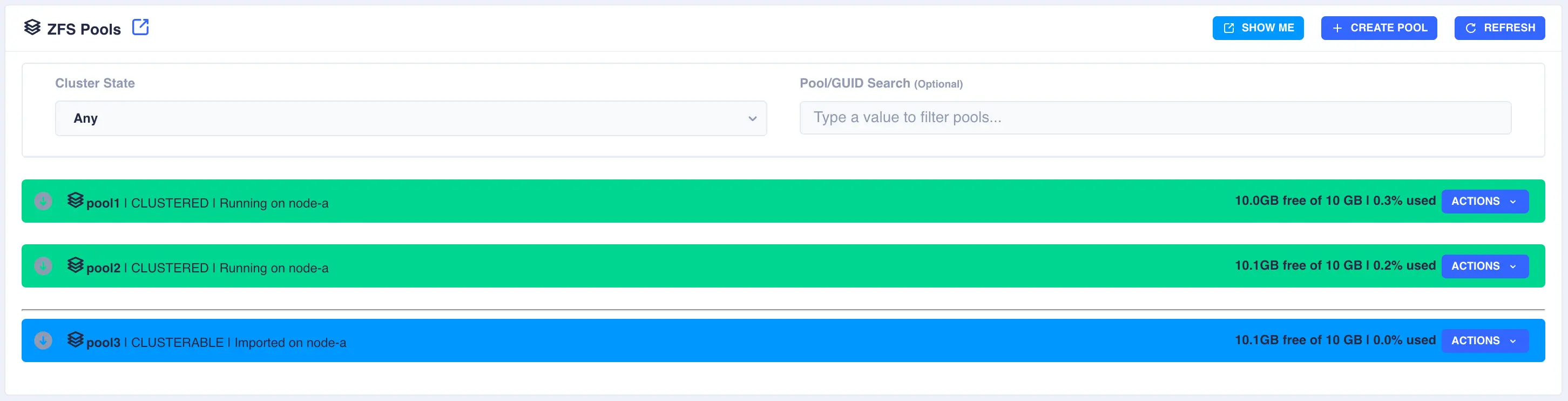
The pool is now ready for clustering.
Unclusterable Pools
Should any issues be encountered when importing the pool it will
be marked as UNCLUSTERABLE. Check the RestAPI log
(/opt/HAC/RSF-1/log/rest-operations.log) for details on why the
import failed.
With a shared-nothingcluster, this may happen if
the pools aren't imported on both nodes.
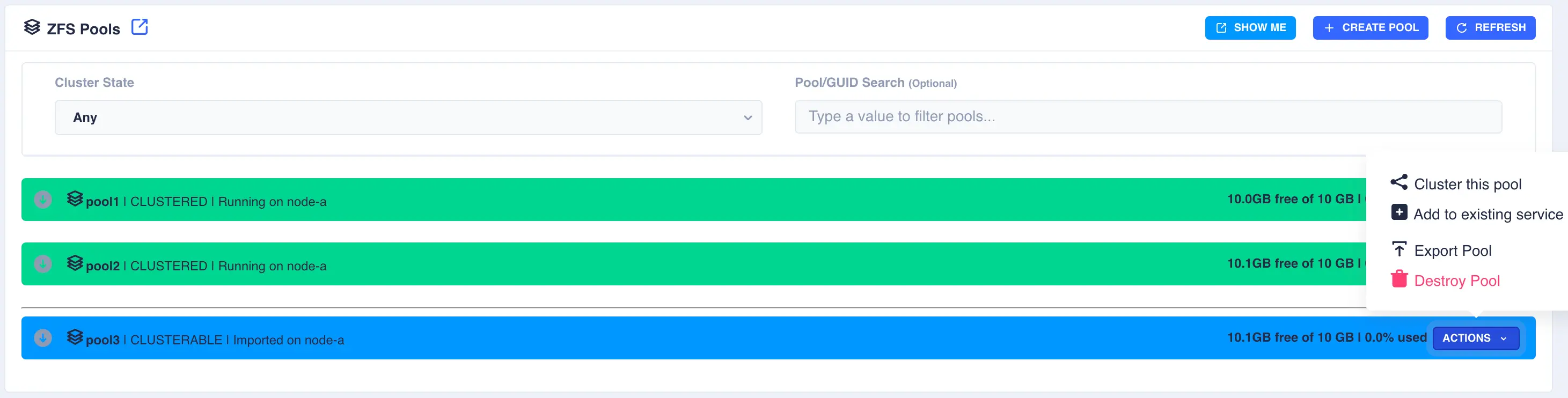
Clustering a Pool
Select the Cluster this pool item from the Actions menu:
Fill out the description and select the preferred node for the service:
What is a preferred node
When a service is started, RSF-1 will initially attempt to run it on it's preferred node. Should that node be unavailable (node is down, service is in manual etc) then the service will be started on the next available node.
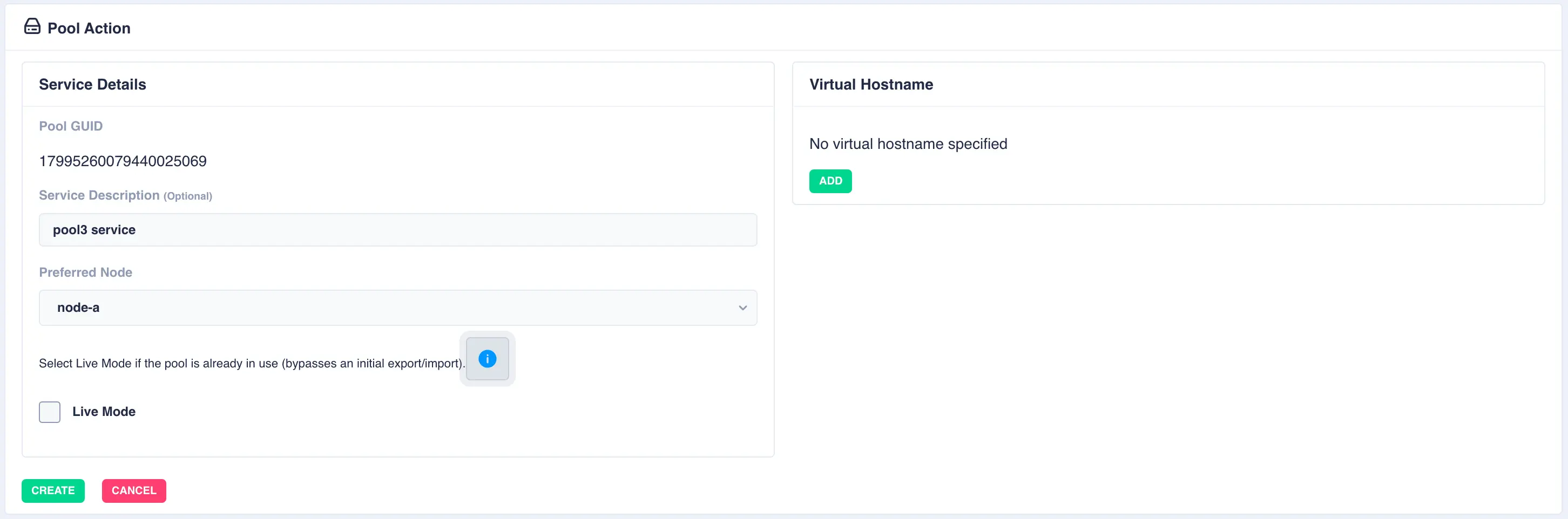
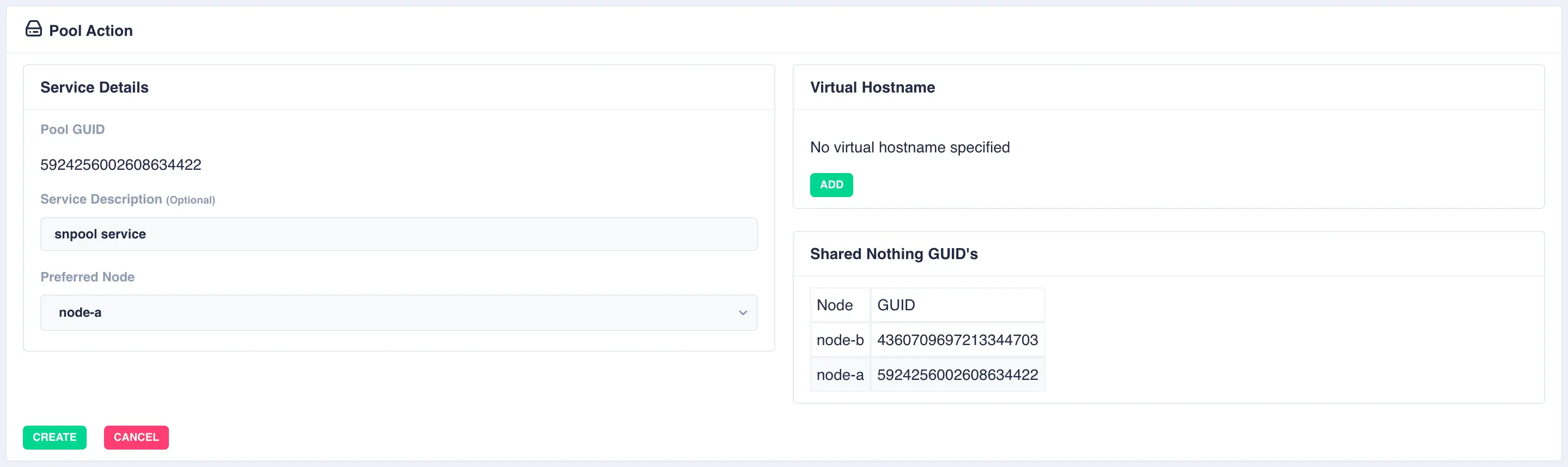
With a shared-nothing pool the GUID's for each pool will be shown:
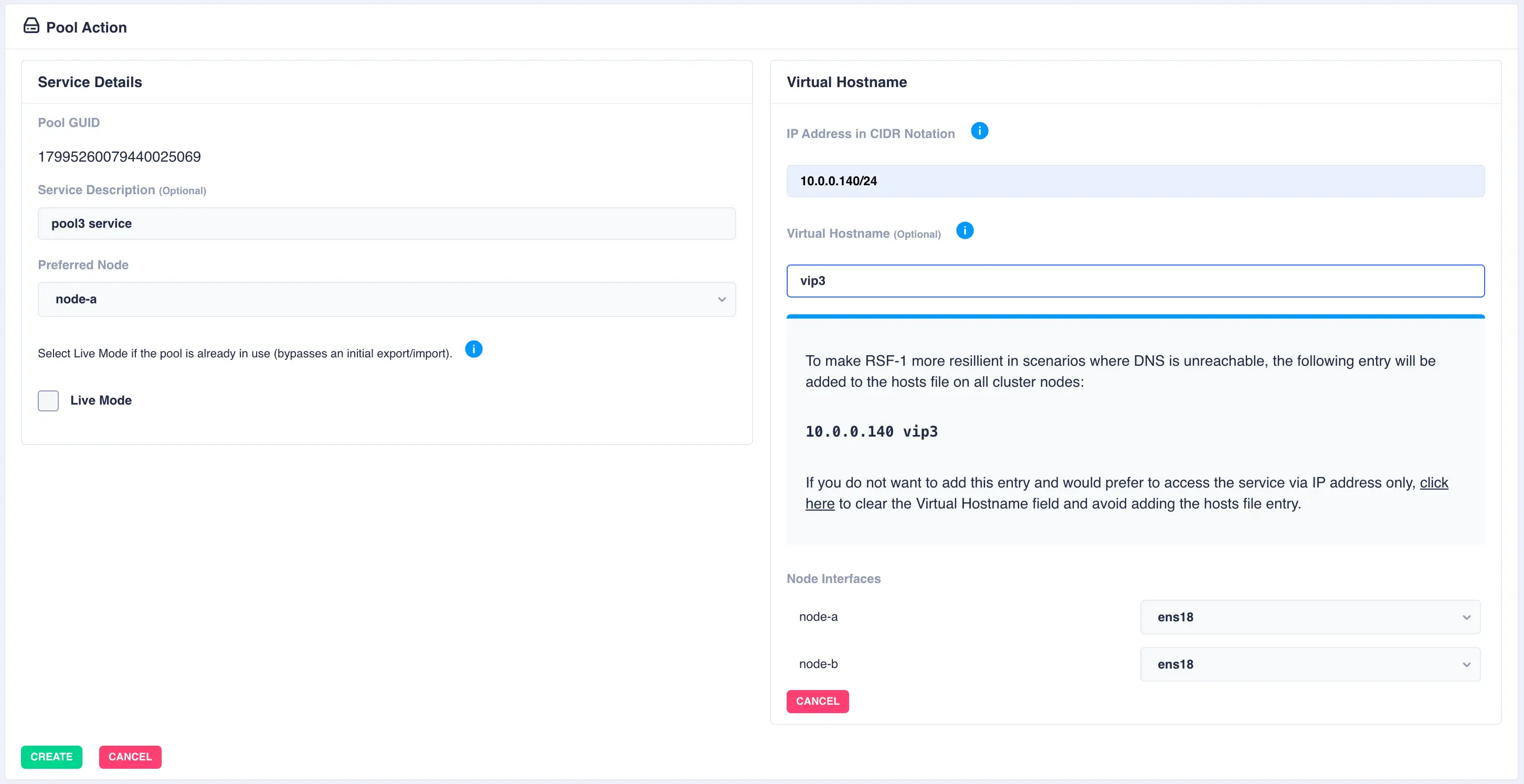
To add a virtual hostname to the service click Add in the Virtual
Hostname panel. Enter the IP address, and optionally a hostname.
For nodes with multiple network interfaces, use the drop down
lists to select which interface the virtual hostname should be assigned
to:
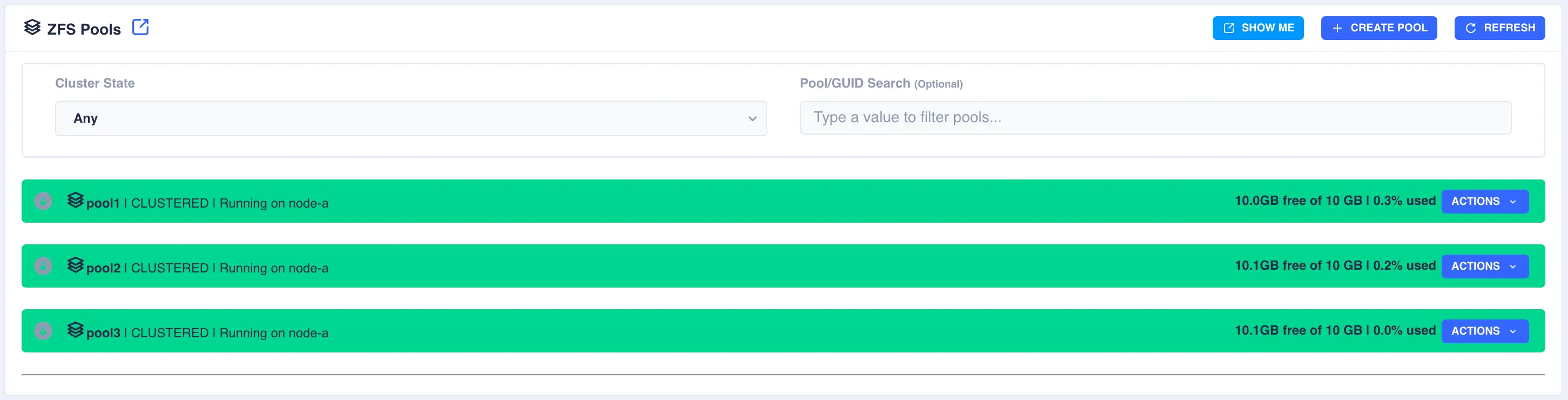
Finally, click the Create button; the pool will now show as CLUSTERED:
Datasets
Creating Datasets
ZFS uses datasets to organize and store data. A ZFS dataset is similar to a mounted filesystem and has its own set of properties, including a quota that limits the amount of data that can be stored. Datasets are organized in the ZFS hierarchy and can have different mountpoints.
The following steps will show the process of creating a dataset within clustered and non clustered pools.
Note
Datasets can only be created or edited on the node where the service is running.
-
To create a dataset navigate to
ZFS -> Datasetsand clickCREATE DATASET:
-
Select the
Parent Pooland enter aDataset Nameand set any options required: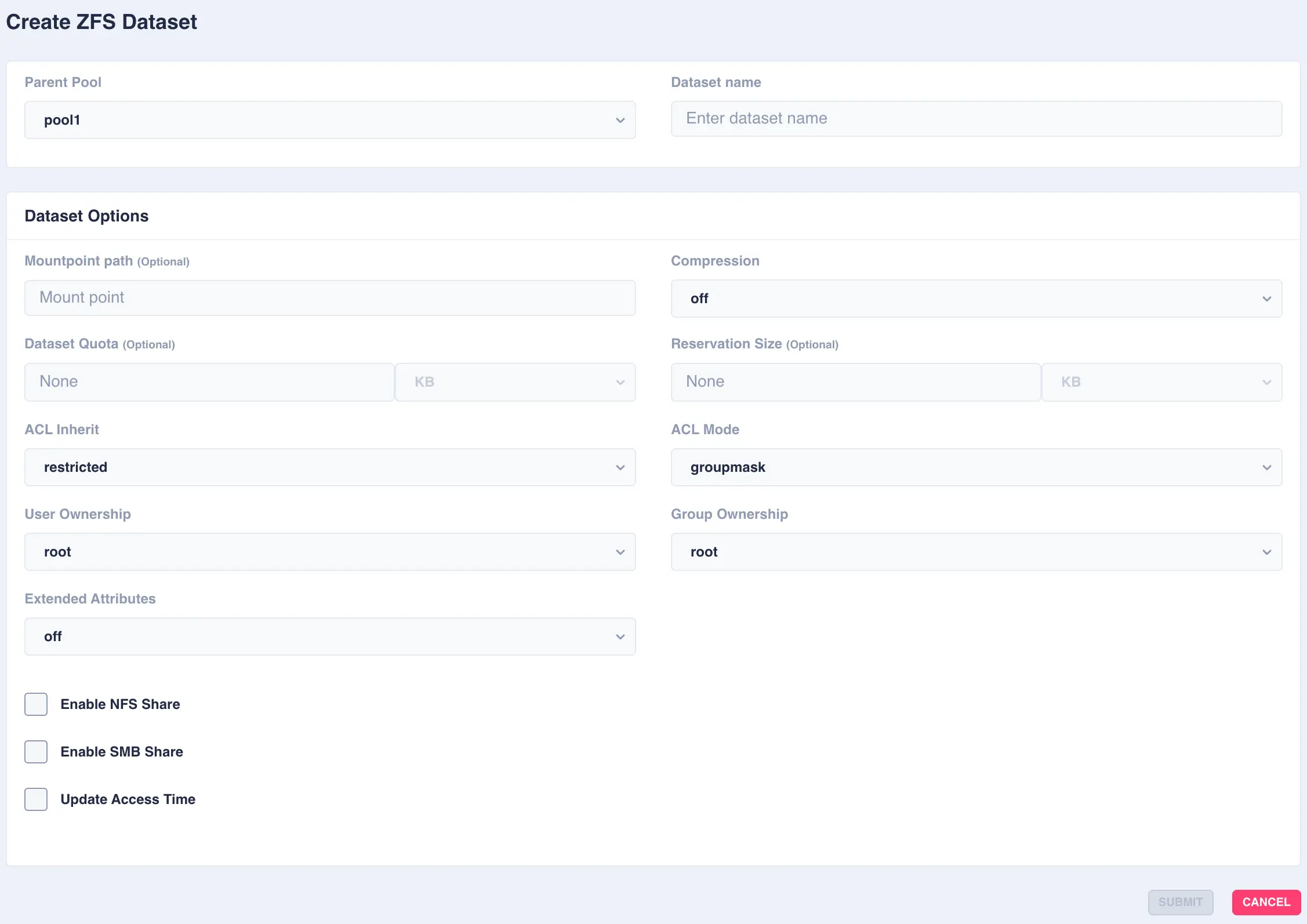
Available options:
OptionDescription Mountpoint pathAlternative path to mount the dataset or pool. Do not change the mountpoint of a clustered pool, doing this will break automatic failover CompressionEnable compression or select an alternative compression type (lz4/zstd) - on - The current default compression algorithm will be used (does not select a fixed compression type; as new compression algorithms are added to ZFS and enabled on a pool, the default compression algorithm may change).
- off - No compression.
- lz4 - A high-performance compression and decompression algorithm, as well as a moderately higher compression ratio than the older lzjb (the original compression algorithm).
- zstd - Provides both high compression ratios and good performance and is preferable over lz4.
Dataset QuotaSet a limit on the amount of disk space a file system can use. Reservation SizeGuarantee a specified amount of disk space is available to a file system. ACL InheritSetermine the behavior of ACL inheritance (i.e. how ACLs are inherited when files and directories are created). The following options are available: - discard - No ACL entries are inherited. The file or directory is created according to the client and protocol being used.
- noallow - Only inheritable ACL entries specifying deny permissions are inherited.
- restricted - Removes the write_acl and write_owner permissions when the ACL entry is inherited, but otherwise leaves inheritable ACL entries untouched. This is the default.
- passthrough - All inheritable ACL entries are inherited. The passthrough mode is typically used to cause all data files to be created with an identical mode in a directory tree. An administrator sets up ACL inheritance so that all files are created with a mode, such as 0664 or 0666.
- passthrough-x - Same as passthrough except that the owner, group, and everyone ACL entries inherit the execute permission only if the file creation mode also requests the execute bit. The passthrough setting works as expected for data files, but you might want to optionally include the execute bit from the file creation mode into the inherited ACL. One example is an output file that is generated from tools, such as cc or gcc. If the inherited ACL does not include the execute bit, then the output executable from the compiler won't be executable until you use chmod(1) to change the file's permissions.
ACL ModeModify ACL behavior whenever a file or directory's mode is modified by the chmod command or when a file is initially created. - discard - All ACL entries are removed except for the entries needed to define the mode of the file or directory.
- groupmask - User or group ACL permissions are reduced so that they are no greater than the group permission bits, unless it is a user entry that has the same UID as the owner of the file or directory. Then, the ACL permissions are reduced so that they are no greater than owner permission bits.
- passthrough - During a chmod operation, ACEs other than owner@, group@, or everyone@ are not modified in any way. ACEs with owner@, group@, or everyone@ are disabled to set the file mode as requested by the chmod operation.
User OwnershipSets the ownership of the dataset Group OwnershipSets the group ownership of the dataset Extended AttributesControls whether extended attributes are enabled for this file system. Two styles of extended attributes are supported: either directory-based or system-attribute-based. - off - Extended attributes are disabled
- on - Extended attributes are enabled; the default value of on enables directory-based extended attributes.
- sa - System based attributes
- dir - Directory based attributes
Enable NFS Shareenable NFS sharing dataset via ZFS. Do not enable if managing Shares via the WebApp. Enable SMB Shareenable SMB sharing dataset via ZFS. Do not enable if managing Shares via the WebApp. Update Access Timecontrols whether the access time for files is updated on read. What is an ACL
An ACL is a list of user permissions for a file, folder, or other data object. The entries in an ACL specify which users and groups can access something and what actions they may perform.
What are Extended Attributes
Extended file attributes are file system features that enable additional attributes to be associated with computer files as metadata not interpreted by the filesystem, whereas regular attributes have a purpose strictly defined by the filesystem.
In ZFS directory based extended attributes (
dir) imposes no practical limit on either the size or number of attributes which can be set on a file. Although under Linux the getxattr(2) and setxattr(2) system calls limit the maximum size to 64K. This is the most compatible style of extended attribute and is supported by all ZFS implementations.With system extended attributes (
sa) the key advantage is improved performance. Storing extended attributes as system attributes significantly decreases the amount of disk I/O required. Up to 64K of data may be stored per-file in the space reserved for system attributes. If there is not enough space available for an extended attribute then it will be automatically written as a directory-based xattr. System-attribute-based extended attributes are not accessible on platforms which do not support the xattr=sa feature. OpenZFS supports xattr=sa on both FreeBSD and Linux. -
Click
SUBMITto create - the Dataset is now created in the pool: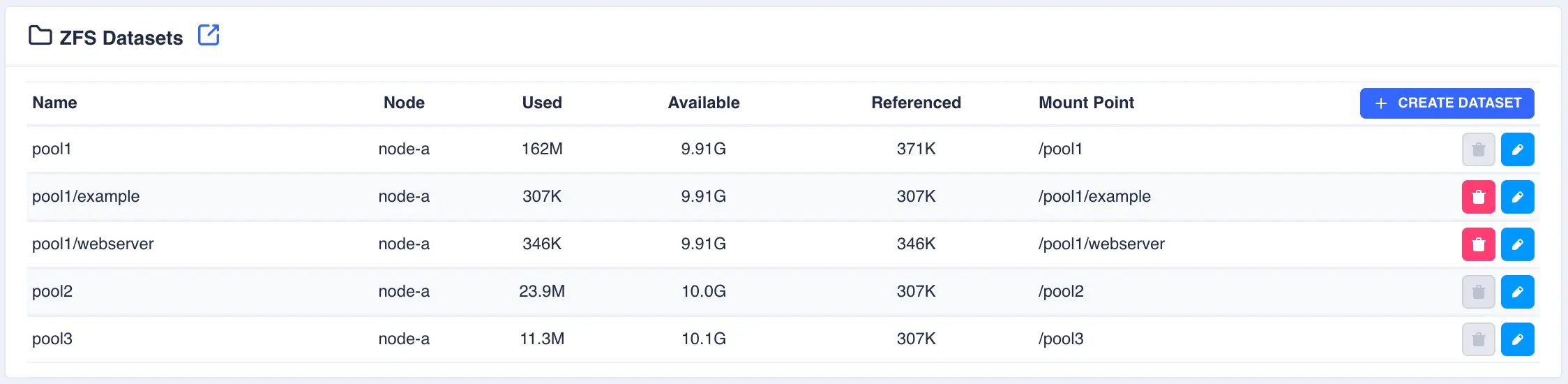
Modifying Datasets
To modify an existing dataset, click the  button to the right of the dataset:
button to the right of the dataset:
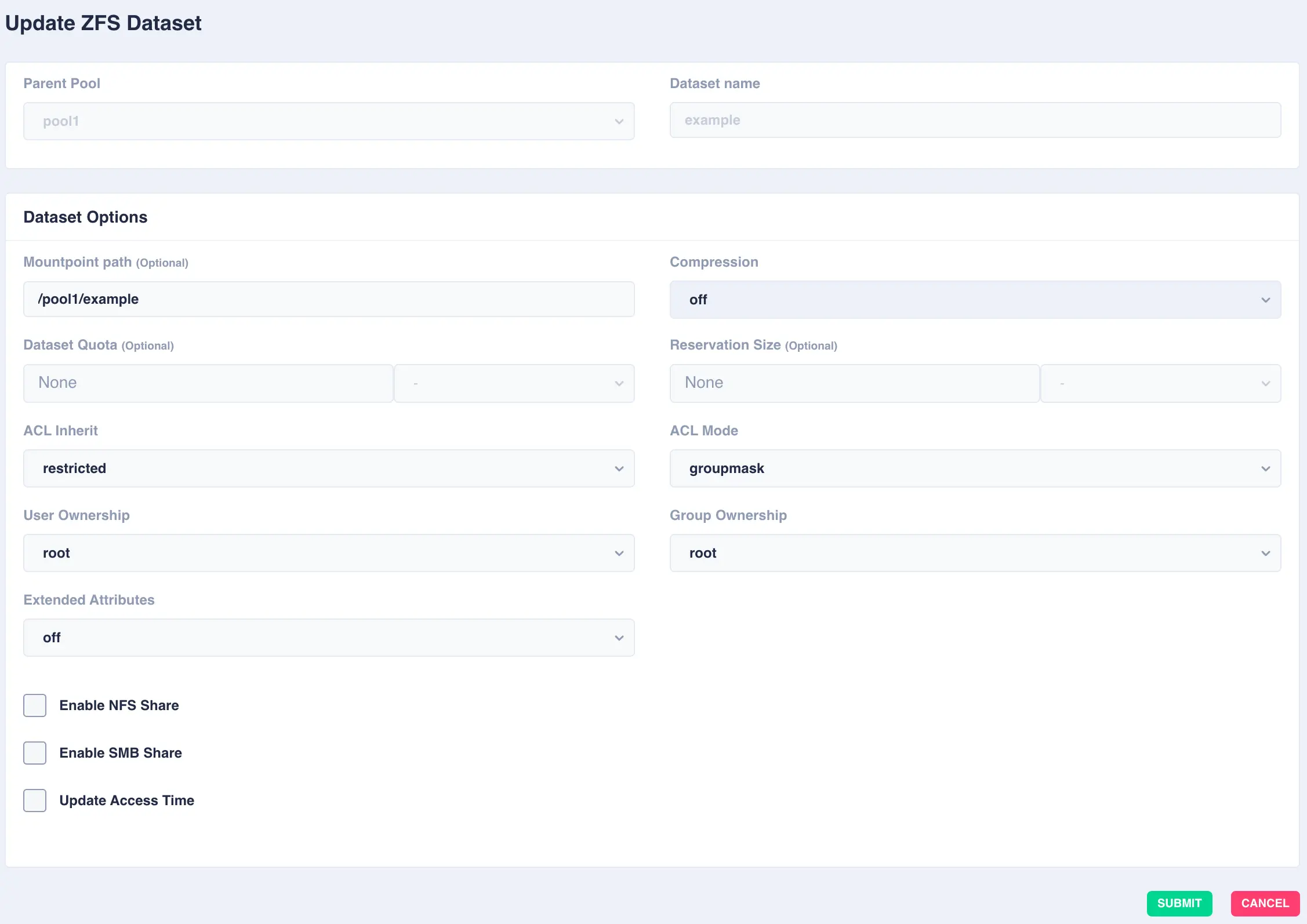
Deleting Datasets
To delete a dataset, click the  button to the right of the dataset and confirm
by clicking the
button to the right of the dataset and confirm
by clicking the REMOVE DATASET option.
Zvols
Creating Zvols
Zvols are block storage devices, cannot be mounted and primarily used for iSCSI backing stores. The size and compression used can be set for each individual backing store.
The following steps will show the process of creating a zvol within clustered and non clustered pools.
Note
Zvols can only be created or edited on the node where the service is running.
-
To create a zvol navigate to
ZFS -> Zvolsand clickCREATE ZVOL:
-
Select the
Parent Pooland enter aZvol Nameand set any options required: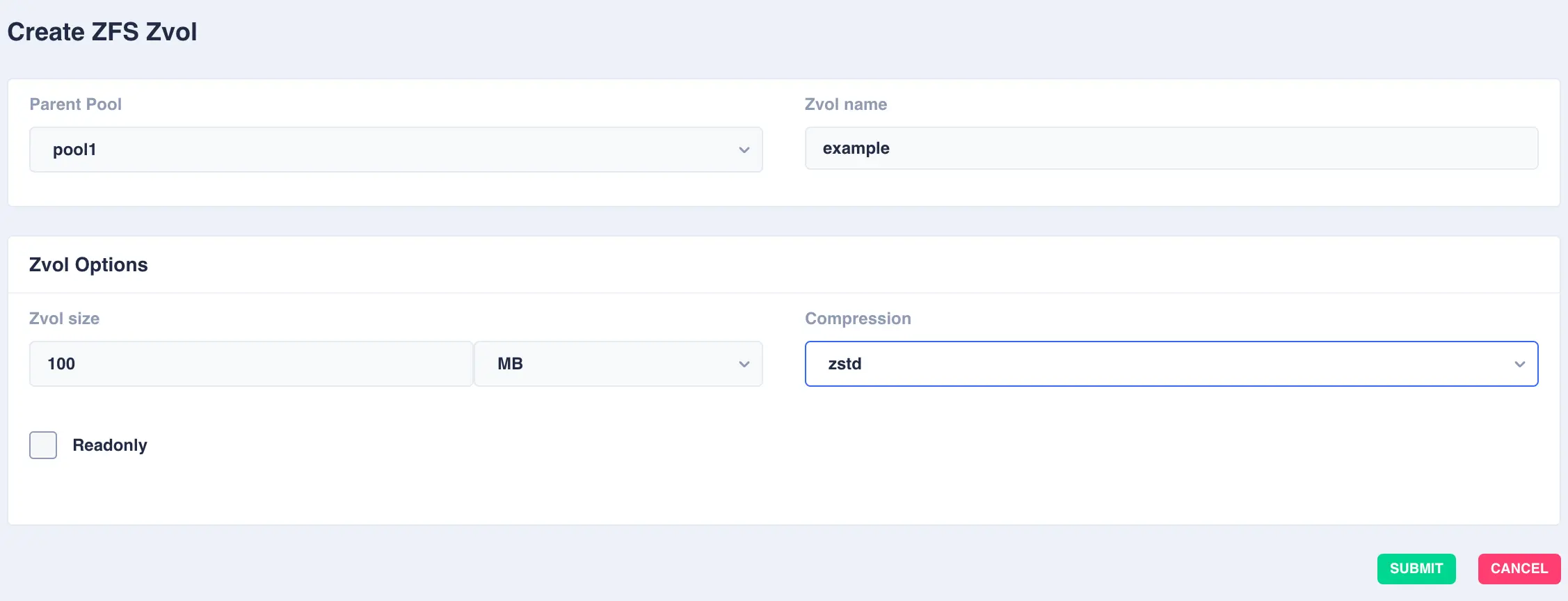
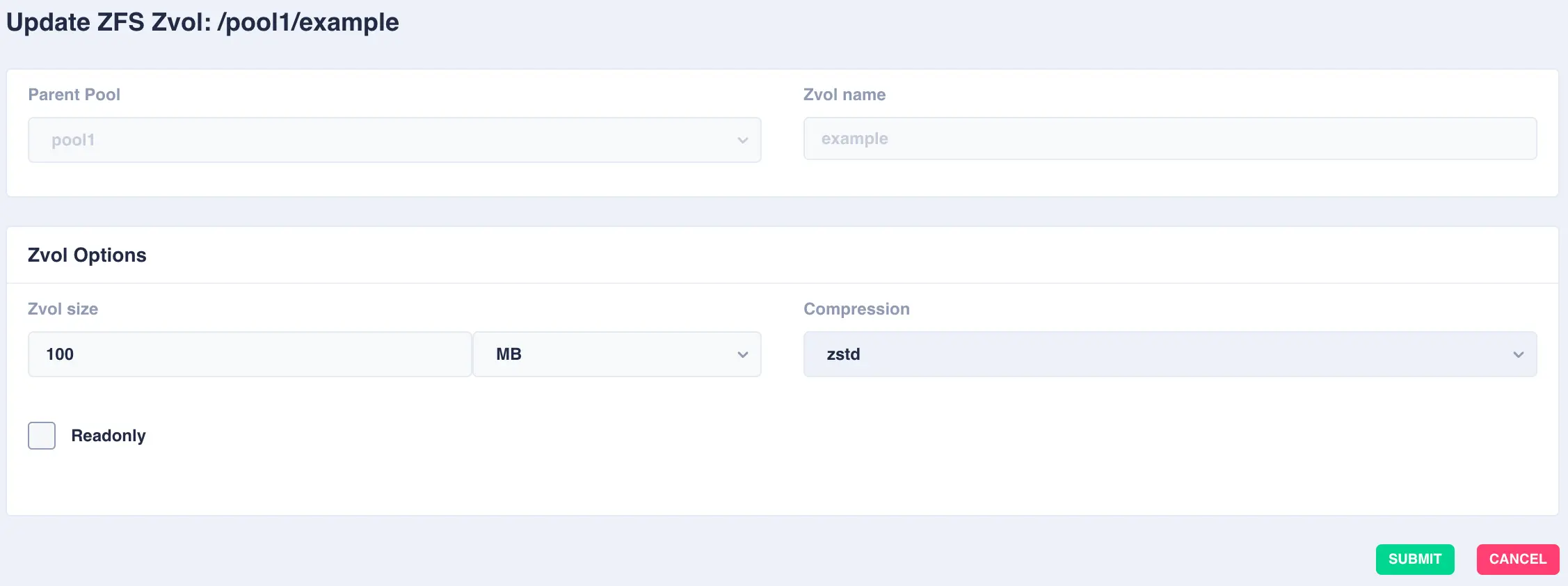
Available options:
OptionDescription Zvols sizeSize of the zvol to create - can be specified in units of KB, MB, GB, TB and PB CompressionEnable compression or select an alternative compression type (lz4/zstd) - on - The current default compression algorithm will be used (does not select a fixed compression type; as new compression algorithms are added to ZFS and enabled on a pool, the default compression algorithm may change).
- off - No compression.
- lz4 - A high-performance compression and decompression algorithm, as well as a moderately higher compression ratio than the older lzjb (the original compression algorithm).
- zstd - Provides both high compression ratios and good performance and is preferable over lz4.
-
Click
SUBMITto create - the Zvol is now created in the pool.
Modifying Zvols
To modify an existing zvol, click the button to the right of the zvol:
Deleting Zvols
To delete a zvol, click the button to the right of the zvol and confirm
by clicking the REMOVE ZVOL option.
Snapshots
Creating Snapshots
A zfs snapshot is a read-only copy of a ZFS dataset or zvol. Snapshots are created almost instantly and initially consume no additional disk space within the pool. They are a valuable tool both for system administrators needing to perform backups and other users who need to save the state of their file system at a particular point in time and possibly restore it later. It is also possible to extract individual files from a snapshot.
The following steps will show the process of creating a snapshot from a clustered pool.
Note
Snapshots cannot be created in shared-nothing clusters as the cluster software itself is responsible for creating and synchronising snapshots at regular intervals.
-
To create a snapshot navigate to
ZFS -> Snapshotsand clickCREATE SNAPSHOT:
-
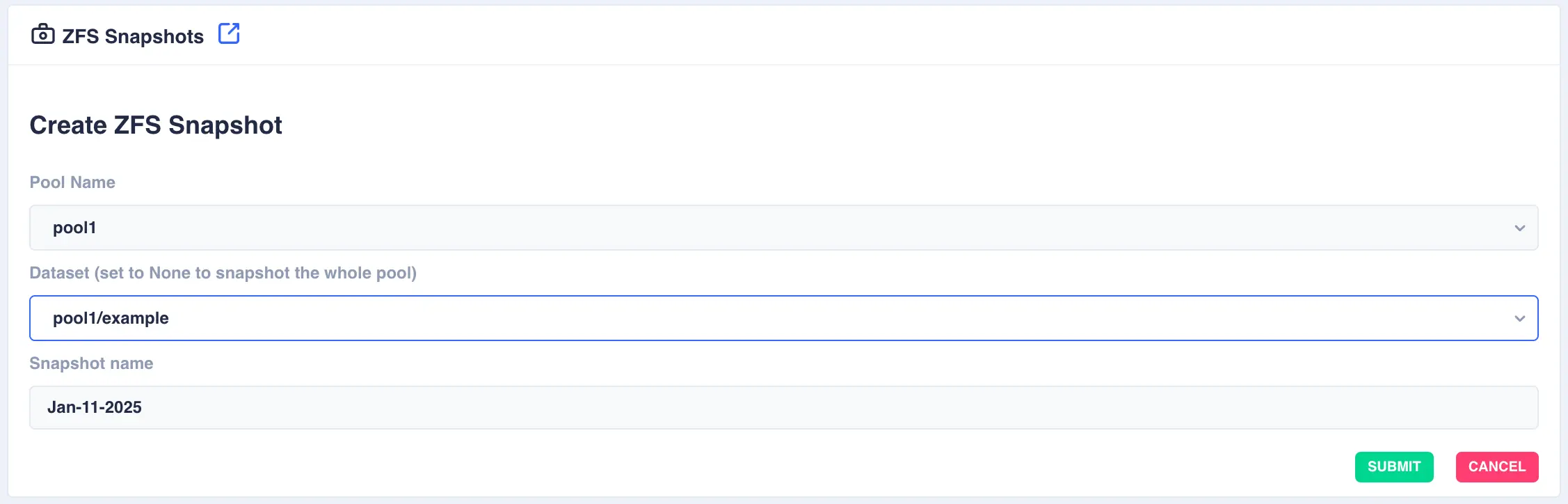
Select the
Pool Nameand theDatasetwithin the pool (set this field toNoneto snapshot the whole of the selected pool). Finally specify a snapshot name and clickSUBMIT:Snapshot name
The cluster software automatically prefixes the snapshot name with pool/dataset name followed by the '@' symbol. Therefore when entering a snapshot name the '@' symbol cannot be used.
-
Click
SUBMITto create - the Zvol is now created in the pool.
Restoring Snapshots
Restoring a snapshot will revert the dataset/pool back to the position it was in when the snapshot was taken. This process is known as rolling back.
Restoration is a one way process
Any changes made to a dataset/pool since the snapshot was taken will be discarded, theerfore use with care.
Deleting Snapshots
Use the DELETE button to remove a snapshot. Once removed any space used by the snapshot will be recovered.